前言
很高兴遇见你~ 欢迎阅读我的文章。
关于Handler的博客可谓是俯拾皆是,而这也是一个老生常谈的话题,可见的他非常基础,也非常重要。但很多的博客,却很少有从入门开始介绍,这在我一开始学习的时候就直接给我讲Looper讲阻塞,非常难以理解。同时,也很少有系统地讲解关于Handler的一切,知识比较零散。我希望写一篇从入门到深入,系统地全面地讲解Handler的文章,帮助大家认识Handler。
这篇文章的讲解深度循序渐进,不同程序的读者可选择对应的部分查看:
- 第一部分是对于Handler的入门概述。了解一个新事物,需要问三个问题:是什么、为什么、怎么用。包括关于Handler的结构等都有介绍。
- 第二部分是在对Handler有一定的认知基础上,对各个类进行详细的讲解和源码分析。
- 第三部分是整体的流程分析以及常见问题的解析。
- 最后一部分是Android对于消息机制设计的讲解以及全文总结。
文章基本涵盖了关于Handler相关的知识,因而篇幅也比较长
考虑过把文章分割成几篇小文章,考虑到阅读的整体性以及方便性,最终还是集成了一篇大文章
文章成体系,全面地讲解知识点,而不是把知识碎片化,否则很难真正去理解单一的知识,更不易于对整体知识的把握
读者可自行选择感兴趣的章节阅读
那么,我们开始吧。
概述
什么是Handler?
准确来说,是Handler机制,Handler只是Handler机制中的一个角色。只是我们对Handler接触比较多,所以经常以Handler来代称。
Handler机制是Android中基于单线消息队列模式的一套线程消息机制。
他的本质是消息机制,负责消息的分发以及处理。这样讲可能有点抽象,不太容易理解。什么是“单线消息队列模式”?什么是“消息”?
通俗点来说,每个线程都有一个“流水线”,我们可往这条流水线上放“消息”,流水线的末端有工作人员会去处理这些消息。因为流水线是单线的,所有消息都必须按照先来后到的形式依次处理(在Handler机制中有“加急线”:同步屏障,这个后面讲)。如下图:
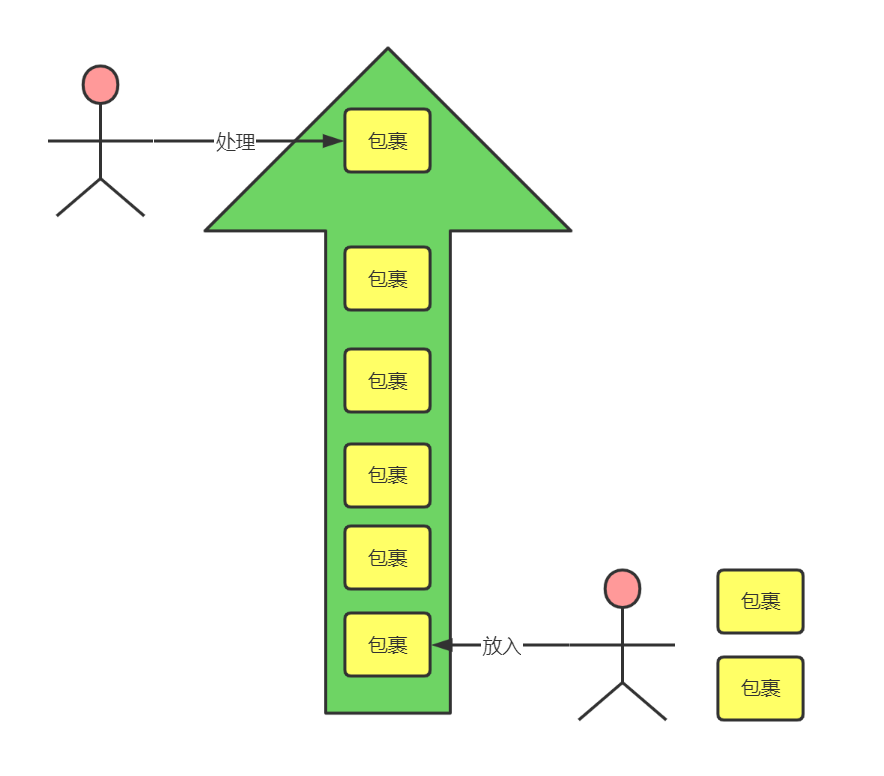
放什么消息以及怎么处理消息,是需要我们去自定义的。Handler机制相当于提供了这样的一套模式,我们只需要“放消息到流水线上”,“编写这些消息的处理逻辑”就可以了,流水线会源源不断把消息运送到末端处理。最后注意重点:每个线程只有一个“流水线”,他的基本范围是线程,负责线程内的通信以及线程间的通信。每个线程可以看成一个厂房,每个厂房只有一个生产线。
两个关键问题
了解Handler的作用前需要了解Handler背景下的两个关键问题:
- 不能在非UI创建线程去操作UI
- 不能在主线程执行耗时任务
我们普遍的认知是:不能在非主线程更新UI。但这是不准确的,如果我们在子线程更新了UI,看看报错信息是什么:

笔者留下了英语渣渣的眼泪,百度翻译一下:
只有创建视图层次结构的原始线程才能访问其视图。但为什么我们一直都说是非主线程不能更新ui?这是因为我们的界面一般都是由主线程进行绘制的,所以界面的更新也就一般都限制在主线程内。这个异常是在viewRootIimpl.checkThread()方法中抛出来的,那可不可以绕过他?当然可以,在他还没创建出来的时候就可以偷偷更新ui了。阅读过Activity启动流程的读者知道,ViewRootImpl是在onCreate方法之后被创建的,所以我们可以在onCreate方法中创建个子线程偷偷更新UI。(Actvity启动流程解析传送门)但还是那句话,可以,但没必要去绕过这个限制,因为这是谷歌为了我们的程序更加安全而设计的。
为什么不能在子线程去更新UI?因为这会让界面产生不可预期的结果。例如主线程在绘制一个按钮,绘制一半另一个线程突然过来把按钮的大小改成两倍大,这个时候再回去主线程继续执行绘制逻辑,这个绘制的效果就会出现问题。所以UI的访问是决不能是并发的。但,子线程又想更新UI,怎么办?加锁。加锁确实可以解决这个问题,但是会带来另外的问题:界面卡顿。锁对于性能是有消耗的,是比较重量级的操作,而ui操作讲究快准狠,加锁会让ui操作性能大打折扣。那有什么更好的方法?Handler就是解决这个问题的。
第二个问题,不能在主线程执行耗时操作。耗时操作包括网络请求、数据库操作等等,这些操作会导致ANR(Application Not Responding)。这个是比较好理解的,没有什么问题,但是这两个问题结合起来,就有大问题了。数据请求一般是耗时操作,必须在子线程进行请求,而当请求完成之后又必须更新UI,UI又只能在主线程更新,这就导致必须切换线程执行代码,上面讨论了加锁是不可取的,那么Handler的重要性就体现出来了。
不用Handler可不可以?可以,但没必要。Handler是谷歌设计来方便开发者切换线程以及处理消息,然后你说我偏不用,我自己用Java工具类,自己弄个出来不可以吗?那。。。请收下小的膝盖。
为什么要有Handler?
先给结论:
- 切换代码执行的线程
- 按顺序规则地处理消息,避免并发
- 阻塞线程,避免让线程结束
- 延迟处理消息
第一个作用是最明显也是最常用的,上一部分已经讲了Handler存在的必要性,android限制了不能在非UI创建线程去操作UI,同时不能在主线程执行耗时任务,所以我们一般是在子线程执行网络请求等耗时操作请求数据,然后再切换到主线程来更新UI。这个时候就必须用到Handler来切换线程了。上面讨论过了这里不再赘述。
这里有一个误区是:我们的activity是执行在主线程的,我们在网络请求完成之后回调主线程的方法不就切换到主线程了吗?咳咳,不要笑,不要觉得这种低级错误太离谱,很多童鞋刚开始接触开发的时候都会犯这个思维错误。这其实是理解错了线程这个概念。代码本身并没有限制运行在哪个线程,代码执行的线程环境取决于你的执行逻辑是在哪个线程。这样讲可能还是有点抽象。例如现在有一个方法void test(){},然后两个不同的线程去调用它:
new Thread(){
// 第一个线程调用
test();
}.start();
new Thread(){
// 第二个线程调用
test();
}此时虽然都是test这个方法,但是他的执行逻辑是由不同的线程调用的,所以他是执行在两个不同的线程环境下。而当我们想要把逻辑切换到另一个线程去执行的时候,就需要用到Handler来切换逻辑。
第二个作用可能看着有点懵。但其实他解决了另一个问题:并发操作。虽然切换线程解决了,如果主线程正在绘制一个按钮,刚测量好按钮的长宽,突然子线程一个新的请求过来打断了,先停下这边的绘制操作,把按钮改成了两倍大,然后逻辑切回来继续绘制,这个时候之前的测量的长宽已经是不准确的了,绘制的结果肯定也不准确。怎么解决?单线消息队列模型。在讲什么是Handler那部分简单介绍过,就是相当于一个流水线一样的模型。子线程的请求会变成一个个的消息,然后主线程依次处理,那么就不会出现绘制一半被打断的问题了。
同时这种模型也不止用于解决ui并发问题,在ActivityThread中有一个H类,他其实就是个Handler。在ActivityThread中定义了一百多中消息类型以及对应的处理逻辑,这样,当需要让ActivityThread处理某一个逻辑的时候,只需要发送对应的消息给他即可,而且可以保证消息按顺序执行,例如先调用onCreate再调用onResume。而如果没有Hanlder的话,就需要让ActivityThread有一百多个接口对外开放,同时还需要不断进行回调保证任务按顺序执行。这显然复杂了非常多。
我们执行一个Java程序的时候,从main方法入口,执行完成之后,马上就退出了,但是我们android应用程序肯定是不可以的,他需要一直等待用户的操作。而Handler机制就解决了这个问题,但消息队列中没有任务的时候,他就会把线程阻塞,等到有新的任务的时候,再重新启动处理消息。
第四个作用让延迟处理消息得到了最佳解决方案。假如你想让应用启动5秒后界面弹出一个对话框,没有handler的情况下,会如何处理?开一个Thread然后使用Thread.sleep让线程睡眠一对应的时间对吧,但如果多个延迟任务呢?而开启线程也是个比较重量级的操作且线程的数量有限。而可以直接给Handler发送延迟对应时间的消息,他会在对应时间之后准时处理该消息(当然有特殊情况,如单件消息处理时间过长或者同步屏障,后面会讲到)。而且无论发送多少延迟消息都不会对性能有任何影响。同时,也是通过这个功能来记录ANR的时间。
讲这些作用可能读者心中并没有一个很形象的概念,也可能看完就忘了。但是关于Handler的定义不能忘:Handler机制是Android中基于单线消息队列模式的一套线程消息机制。,上述四个作用是为了让读者更好地理解Handler机制。
如何使用Handler
我们平常使用Handler有两种不同的创建方式,但总体流程是相同的:
- 创建Looper
- 使用Looper创建Handler
- 启动Looper
- 使用Handler发送信息
Looper可理解为循环器,就像“流水线”上的滚带,后面会详细讲到。每个线程只有一个Looper,通常主线程已经创建好了,追溯应用程序启动流程可以知道启动过程中调用了Looper.prepareMainLooper,而在子线程就必须使用如下方法来初始化Looper:
Looper.prepare();第二步是创建Handler,也是最熟悉的一步。我们有两种方法来创建Handler:传入callBack对象和继承。如下:
public class MainActivity extends AppComposeActivity{
...;
// 第一种方法:使用callBack创建handler
public void onCreate(Bundle savedInstanceState){
super.onCreate(savedInstanceState);
Handler handler = Handler(Looper.myLooper(),new CallBack(){
public Boolean handleMessage(Message msg) {
TODO("Not yet implemented")
}
});
}
// 第二种方法:继承Handler并重写handlerMessage方法
static MyHandler extends Hanlder{
public MyHandler(Looper looper){
super(looper);
}
@Override
public void handleMessage(Message msg){
super.handleMessage(msg);
// TODO(重写这个方法)
}
}
}注意第二种方法,要使用静态内部类,不然可能会造成内存泄露。原因是非静态内部类会持有外部类的引用,而Handler发出的Message会持有Handler的引用。如果这个Message是个延迟的消息,此时activity被退出了,但Message依然在“流水线”上,Message->handler->activity,那么activity就无法被回收,导致内存泄露。
两种Handler的写法各有千秋,继承法可以写比较复杂的逻辑,callback法适合比价简单的逻辑,看具体的业务来选择。
然后再调用Looper的loope方法来启动Looper:
Looper.loop();最后就是使用Handler来发送信息了。当我们获得handler的实例之后,就可以通过他的sendMessage相方法和post相关方法来发送信息,如下:
handler.sendMessage(msg);
handler.sendMessageDelayed(msg,delayTime);
handler.post(runnable);
handler.postDelayed(runnable,delayTime);然后一般情况下是哪个Handler发出的信息,最终由哪个Handler来处理。这样,只要我们拿到Handler对象,就可以往对应的线程发送信息了。
Handler内部模式结构
经过前面的介绍对于Looper已经有了一定的认知,但可能对他内部的模式还不太清楚。这一部分先讲解Handler的大概内部模式,目的是为下面的详解做铺垫,为做整体概念感知。先上图:
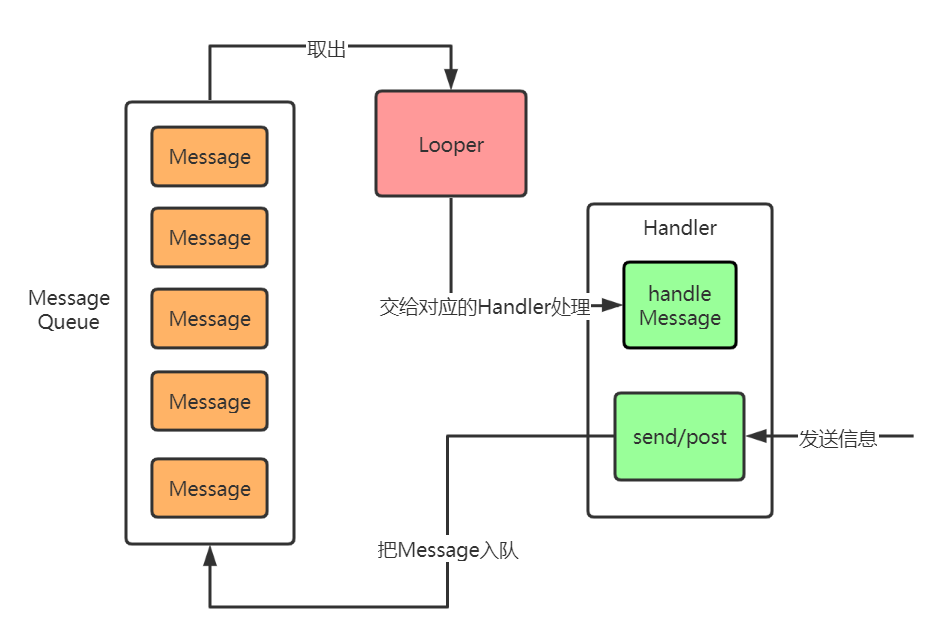
Handler机制内部有三大关键角色:Handler,Looper,MessageQueue。其中MessageQueue是Looper内部的一个对象,MessageQueue和Looper每个线程有且只有一个,而Handler是可以有很多个的。他们的工作流程是:
- 用户使用线程的Looper构建Handler之后,通过Handler的send和post方法发送消息
- 消息会加入到MessageQueue中,等待Looper获取处理
- Looper会不断地从MessageQueue中获取Message然后交付给对应的Handler处理
这就是大名鼎鼎的Handler机制内部模式了,说难,其实也是很简单。
Handler机制关键类
一、ThreadLocal
概述
ThreadLocal是Java中一个用于线程内部存储数据的工具类。
ThreadLocal是用来存储数据的,但是每个线程只能访问到各自线程的数据。我们一般的用法是:
ThreadLocal<String> stringLocal = new ThreadLocal<>();
stringLocal.set("java");
String s = stringLocal.get();不同的线程之间访问到的数据是不一样的:
public static void main(String[] args){
ThreadLocal<String> stringLocal = new ThreadLocal<>();
stringLocal.set("java");
System.out.println(stringLocal.get());
new Thread(){
System.out.println(stringLocal.get());
}
}
结果:
java
null线程只能访问到自己线程存储的数据。
ThreadLocal的作用
ThreadLocal的特性适用于同样的数据类型,不同的线程有不同的备份情况,如我们这篇文章一直在讲的Looper。每个线程都有一个对象,但是不同线程的Looper是不一样的,这个时候就特别适合使用ThreadLocal来存储数据,这也是为什么这里要讲ThreadLocal的原因
ThreadLocal内部结构
ThreadLocal的内部机制结构如下:
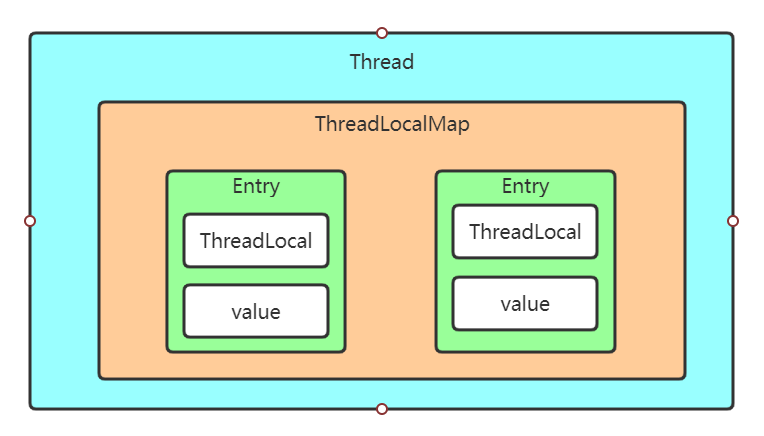
每个Thread,也就是每个线程内部维护有一个ThreadLocalMap,ThreadLocalMap内部存储多个Entry。Entry可以理解为键值对,他的本质是一个弱引用,内部有一个object类型的内部变量,如下:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}Entry是ThreadLocalMap的一个静态内部类,这样每个Entry里面就维护了一个ThreadLocal和ThreadLocal泛型对象。每个线程的内部维护有一个Entry数组,并通过hash算法使得读取数据的速度达到O(1)。由于不同的线程对应的Thread对象不同,所以对应的ThreadLocalMap肯定也不同,这样只有获取到Thread对象才能获取到其内部的数据,数据就被隔离在不同的线程内部了。
ThreadLocal工作流程
那ThreadLocal是怎么实现把数据存储在不同线程中的?先从他的set方法入手:
TheadLocal.class
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}逻辑不是很复杂,首先获取当前线程的Thread对象,然后再获取Thread的ThreadLocalMap对象,如果该map对象不存在则创建一个并调用他的set方法把数据存储起来。我们继续看ThreadLocalMap的set方法:
ThreadLocalMap.class
private void set(ThreadLocal<?> key, Object value) {
// 每个ThreadLocalMap内部都有一个Entry数组
Entry[] tab = table;
int len = tab.length;
// 获取新的ThreadLocal在Entry数组中的下标
int i = key.threadLocalHashCode & (len-1);
// 判断当前位置是否发生了Hash冲突
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
// 如果数据存在且相同则直接返回
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
// 若当前位置没有其他元素则直接把新的Entry对象放入
tab[i] = new Entry(key, value);
int sz = ++size;
// 判断是否需要对数组进行扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}这里的逻辑和HashMap是很像的,我们可以直接使用HashMap的思维来理解ThreadLocalMap:ThreadLocalMap的key是ThreadLocal,value是ThreadLocal对应的泛型。他的存储步骤如下:
- 根据自身的threadLocalHashCode与数组的长度进行相与得到下标
- 如果此下标为空,则直接插入
- 如果此下标已经有元素,则判断两者的ThreadLocal是否相同,相同则更新value后返回,否则找下一个下标
- 直到找到合适的位置把entry对象插入
- 最后判断是否需要对entry数组进行扩容
是不是和HashMap非常像?和HashMap的不同是:hash算法不一样,以及这里使用的是开发地址法,而HashMap使用的是链表法。ThreadLocalMap牺牲一定的空间来换取更快的速度。具体的Hash算法这里就不再深入了,有兴趣的读者可以阅读这篇文章ThreadLocal传送门
然后继续看ThreadLocal的get方法:
ThreadLocal.class
public T get() {
// 获取当前线程的ThreadLocalMap
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
// 根据ThreadLocal获取Entry对象
ThreadLocalMap.Entry e = map.getEntry(this);
// 如果没找到也会执行初始化工作
if (e != null) {
@SuppressWarnings("unchecked")
// 把获取到的对象进行返回
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}前面讲到ThreadLocalMap其实非常像一个HashMap,他的get方法也是一样的。使用ThreadLocal作为key获取到对应的Entry,再把value返回即可。如果map尚未初始化则会执行初始化操作。下面继续看下ThreadLocalMap的get方法:
ThreadLocalMap.class
private Entry getEntry(ThreadLocal<?> key) {
// 根据hash算法找到下标
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
// 找到数据则返回,否则通过开发地址法寻找下一个下标
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}利用ThreadLocal的threadLocalHashCode得到下标,然后根据下标找到数据。没找到则根据算法寻找下个下标。
内存泄露问题
我们会发现Entry中,ThreadLocal是一个弱引用,而value则是强引用。如果外部没有对ThreadLocal的任何引用,那么ThreadLocal就会被回收,此时其对应的value也就变得没有意义了,但是却无法被回收,这就造成了内存泄露。怎么解决?在ThreadLocal回收的时候记得调用其remove方法把entry移除,防止内存泄露。
ThreadLocal总结
ThreadLocal适合用于在不同线程作用域的数据备份
ThreadLocal机制通过在每个线程维护一个ThreadLocalMap,其key为ThreadLocal,value为ThreadLocal对应的泛型对象,这样每个ThreadLocal就可以作为key将不同的value存储在不同Thread的Map中,当获取数据的时候,同个ThreadLocal就可以在不同线程的Map中得到不同的数据,如下图:
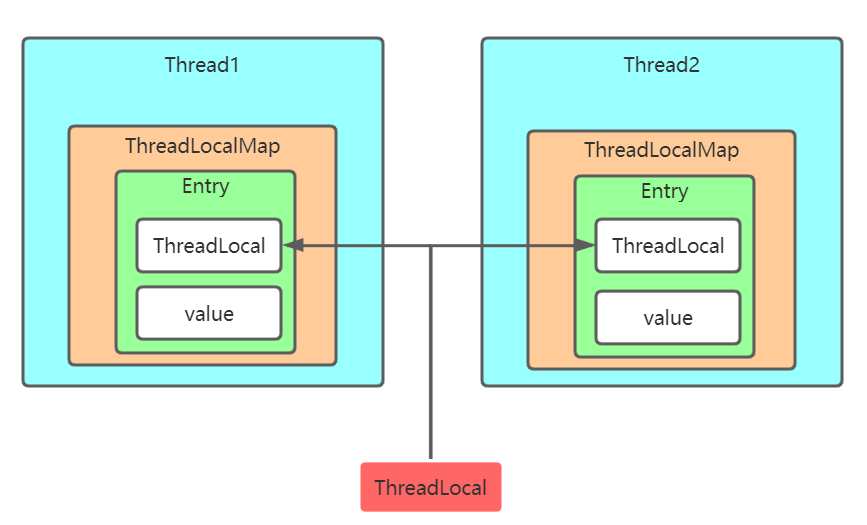
ThreadLocalMap类似于一个改版的HashMap,内部也是使用数组和Hash算法来存储数据,使得存储和读取的速度非常快。
同时使用ThreadLocal需要注意内存泄露问题,当ThreadLocal不再使用的时候,需要通过remove方法把value移除。
二、Message
概述
Message是负责承载消息的类,主要是关注他的内部属性:
// 用户自定义,主要用于辨别Message的类型
public int what;
// 用于存储一些整型数据
public int arg1;
public int arg2;
// 可放入一个可序列化对象
public Object obj;
// Bundle数据
Bundle data;
// Message处理的时间。相对于1970.1.1而言的时间
// 对用户不可见
public long when;
// 处理这个Message的Handler
// 对用户不可见
Handler target;
// 当我们使用Handler的post方法时候就是把runnable对象封装成Message
// 对用户不可见
Runnable callback;
// MessageQueue是一个链表,next表示下一个
// 对用户不可见
Message next;循环利用Message
当我们获取Message的时候,官方建议是通过Message.obtain()方法来获取,当使用完之后使用recycle()方法来回收循环利用。而不是直接new一个新的对象:
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag
sPoolSize--;
return m;
}
}
return new Message();
}Message维护了一个静态链表,链表头是sPool,Message有一个next属性,Message本身就是链表结构。sPoolSync是一个object对象,仅作为解决并发访问安全设计。当我们调用obtain来获取一个新的Message的时候,首先会检查链表中是否有空闲的Message,如果没有则新建一个返回。
当我们使用完成之后,可以调用Message的recycle方法进行回收:
public void recycle() {
if (isInUse()) {
if (gCheckRecycle) {
throw new IllegalStateException("This message cannot be recycled because it "
+ "is still in use.");
}
return;
}
recycleUnchecked();
}如果这个Message正在使用则会抛出异常,否则则调用recycleUnchecked进行回收:
void recycleUnchecked() {
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = UID_NONE;
workSourceUid = UID_NONE;
when = 0;
target = null;
callback = null;
data = null;
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
next = sPool;
sPool = this;
sPoolSize++;
}
}
}这个方法的逻辑也非常简单,把Message中的内容清空,然后判断链表是否达到最大值(50),然后插入链表中。
Message总结
Message的作用就是承载消息,他的内部有很多的属性用于给用户赋值。同时Message本身也是一个链表结构,无论是在MessageQueue还是在Message内部的回收机制,都是使用这个结构来形成链表。同时官方建议不要直接初始化Message,而是通过Message.obtain()方法来获取一个Message循环利用。一般来说我们不需要去调用recycle进行回收,在Looper中会自动把Message进行回收,后面会讲到。
三、MessageQueue
概述
每个线程都有且只有一个MessageQueue,他是一个用于承载消息的队列,内部使用链表作为数据结构,所以待处理的消息都会在这里排队。前面讲到ThreadLocalMap是一个“修改版的HashMap”,而MessageQueue就是一个“修改版的LinkQueue”。他也有两个关键的方法:入队(enqueueMessage)和出队(next)。这也是MessageQueue的重点所在。
Message还涉及到一个关键概念:线程休眠。当MessageQueue中没有消息或者都在等待中,则会将线程休眠,让出cpu资源,提高cpu的利用效率。进入休眠后,如果需要继续执行代码则需要将线程唤醒。当方法暂时无法直接返回需要等待的时候,则可以将线程阻塞,即休眠,等待被唤醒继续执行逻辑。这部分内容也会在后面详细讲。
关键方法
出队 – next()
next方法主要是做消息出队工作。
Message next() { // 如果looper已经退出了,这里就返回null final long ptr = mPtr; if (ptr == 0) { return null; } ... // 阻塞时间 int nextPollTimeoutMillis = 0; for (;;) { if (nextPollTimeoutMillis != 0) { Binder.flushPendingCommands(); } // 阻塞对应时间 nativePollOnce(ptr, nextPollTimeoutMillis); // 对MessageQueue进行加锁,保证线程安全 synchronized (this) { final long now = SystemClock.uptimeMillis(); Message prevMsg = null; Message msg = mMessages; ... if (msg != null) { if (now < msg.when) { // 下一个消息还没开始,等待两者的时间差 nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE); } else { // 获得消息且现在要执行,标记MessageQueue为非阻塞 mBlocked = false; // 链表操作 if (prevMsg != null) { prevMsg.next = msg.next; } else { mMessages = msg.next; } msg.next = null; msg.markInUse(); return msg; } } else { // 没有消息,进入阻塞状态 nextPollTimeoutMillis = -1; } ... } }代码很长,其中还涉及了同步屏障和IdleHandler,这两部分内容我放在后面讲,这里先讲主要的出队逻辑。代码中我都加了注释,这里还是再讲一下。next方法目的是获取MessageQueue中的一个Message,如果队列中没有消息的话,就会把方法阻塞住,等待新的消息来唤醒。主要步骤如下:
- 如果Looper已经退出了,直接返回null
- 进入死循环,直到获取到Message或者退出
- 循环中先判断是否需要进行阻塞,阻塞结束后,对MessageQueue进行加锁,获取Message
- 如果MessageQueue中没有消息,则直接把线程无限阻塞等待唤醒;
- 如果MessageQueue中有消息,则判断是否需要等待,否则则直接返回对应的message。
可以看到逻辑就是判断当前时间Message中是否需要等待。其中
nextPollTimeoutMillis表示阻塞的时间,-1表示无限时间,只有通过唤醒才能打破阻塞。入队 – enqueueMessage()
MessageQueue.class boolean enqueueMessage(Message msg, long when) { // Hanlder不允许为空 if (msg.target == null) { throw new IllegalArgumentException("Message must have a target."); } if (msg.isInUse()) { throw new IllegalStateException(msg + " This message is already in use."); } // 对MessageQueue进行加锁 synchronized (this) { // 判断目标thread是否已经死亡 if (mQuitting) { IllegalStateException e = new IllegalStateException( msg.target + " sending message to a Handler on a dead thread"); Log.w(TAG, e.getMessage(), e); msg.recycle(); return false; } // 标记Message正在被执行,以及需要被执行的时间,这里的when是距离开机的时间 msg.markInUse(); msg.when = when; // p是MessageQueue的链表头 Message p = mMessages; boolean needWake; // 判断是否需要唤醒MessageQueue // 如果有新的队头,同时MessageQueue处于阻塞状态则需要唤醒队列 if (p == null || when == 0 || when < p.when) { msg.next = p; mMessages = msg; needWake = mBlocked; } else { ... // 根据时间找到插入的位置 Message prev; for (;;) { prev = p; p = p.next; if (p == null || when < p.when) { break; } ... } msg.next = p; prev.next = msg; } // 如果需要则唤醒队列 if (needWake) { nativeWake(mPtr); } } return true; }这部分的代码好像也很多,但是逻辑也是不复杂,主要就是链表操作以及判断是否需要唤醒MessageQueue,代码中我加了一些注释,下面再总结一下:
首先判断message的目标handler不能为空且不能正在使用中
对MessageQueue进行加锁
判断目标线程是否已经死亡,死亡则直接返回false
初始化Message的执行时间以及标记正在执行中
然后根据Message的执行时间,找到在链表中的插入位置进行插入
同时判断是否需要唤醒MessageQueue。有两种情况需要唤醒:当新插入的Message在链表头时,如果messageQueue是空的或者正在等待下个任务的延迟时间执行,这个时候就需要唤醒MessageQueue。
MessageQueue总结
Message两大重点:阻塞休眠和队列操作。基本都是围绕着两点来展开。而源码中还涉及到了同步屏障以及IdleHandler,这两部分内容我分开到了最后一部分的相关问题中讲。平时用的比较少,但也是比较重要的内容。
四、Looper
概述
Looper可以说是Handler机制中的一个非常重要的核心。Looper相当于线程消息机制的引擎,驱动整个消息机制运行。Looper负责从队列中取出消息,然后交给对应的Handler去处理。如果队列中没有消息,则MessageQueue的next方法会阻塞线程,等待新的消息的到来。每个线程有且只能有一个“引擎”,也就是Looper,如果没有Looper,那么消息机制就运行不起来,而如果有多个Looper,则会违背单线操作的概念,造成并发操作。
每个线程仅有一个Looper,由不同Looper分发的Message运行在不同的线程中。Looper的内部维护一个MessageQueue,当初始化Looper的时候会顺带初始化MessageQueue。
Looper使用ThreadLocal来保证每个线程都有且只有一个相同的副本。
关键方法
prepare : 初始化Looper
Looper.class static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>(); public static void prepare() { prepare(true); } // 最终调用到了这个方法 private static void prepare(boolean quitAllowed) { if (sThreadLocal.get() != null) { throw new RuntimeException("Only one Looper may be created per thread"); } sThreadLocal.set(new Looper(quitAllowed)); }每个线程使用Handler之前,都必须调用
Looper.prepare()方法来初始化当前线程的Looper。参数quitAllowed表示该Looper是否可以退出。主线程的Looper是不能退出的,不然程序就直接终止了。我们在主线程使用Handler的时候是不用初始化Looper的,为什么?因为Activiy在启动的时候就已经帮我们初始化主线程Looper了,这点在后面再详细展开。所以在主线程我们可以直接调用Looper.myLooper()获取当前线程的Looper。prepare方法重点在
sThreadLocal.set(new Looper(quitAllowed));,可以看出来这里使用了ThreadLocal来创建当前线程的Looper对象副本。如果当前线程已经有Looper了,则会抛出异常。sThreadLocal是Looper类的静态变量,前面我们介绍过了ThreadLocal了,这里每个线程调用一次prepare方法就可以初始化当前线程的Looper了。接下来再看到Looper的构造方法:
private Looper(boolean quitAllowed) { mQueue = new MessageQueue(quitAllowed); mThread = Thread.currentThread(); }逻辑很简单,初始化了一个MessageQueue,再把当前的线程的Thread对象赋值给mThread。
myLooper() : 获取当前线程的Looper对象
获取当前线程的Looper对象。这个方法就是直接调用ThreadLocal的get方法:
public static @Nullable Looper myLooper() { return sThreadLocal.get(); }
loop() : 循环获取消息
当Looper初始化完成之后,他是不会自己启动的,需要我们自己去启动Looper,调用Looper的
loop()方法即可:public static void loop() { // 获取当前线程的Looper final Looper me = myLooper(); if (me == null) { throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread."); } final MessageQueue queue = me.mQueue; ... for (;;) { // 获取消息队列中的消息 Message msg = queue.next(); // might block if (msg == null) { // 返回null说明MessageQueue退出了 return; } ... try { // 调用Message对应的Handler处理消息 msg.target.dispatchMessage(msg); if (observer != null) { observer.messageDispatched(token, msg); } dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0; } ... // 回收Message msg.recycleUnchecked(); } }loop()方法就是Looper这个“引擎”的核心所在。首先获取当前线程的Looper对象,没有则抛出异常。然后进入一个死循环:不断调用MessageQueue的next方法来获取消息,然后调用message的目标handler的dispatchMessage方法来处理Message。
前面我们了解过了MessageQueue,next方法是可能会进行阻塞的:当MessageQueue为空或者目前没有任何消息需要处理。所以Looper就会一直等待,阻塞在里,线程也就不会结束。当我们退出Looper的时候,next方法会返回null,那么Looper也就会跟着结束了。
同时,因为Looper是运行在不同线程的逻辑,其调用的dispatchMessage方法也是运行在不同的线程,这就达到了切换线程的目的。
quit/quitSafely : 退出Looper
quit是直接将Looper退出,quitSafely是将MessageQueue中的不需要等待的消息处理完成之后再退出,看一下代码:
public void quit() { mQueue.quit(false); } // 最终都是调用到了这个方法 void quit(boolean safe) { // 如果不能退出则抛出异常。这个值在初始化Looper的时候被赋值 if (!mQuitAllowed) { throw new IllegalStateException("Main thread not allowed to quit."); } synchronized (this) { // 退出一次之后就无法再次运行了 if (mQuitting) { return; } mQuitting = true; // 执行不同的方法 if (safe) { removeAllFutureMessagesLocked(); } else { removeAllMessagesLocked(); } // 唤醒MessageQueue nativeWake(mPtr); } }我们可以发现最后都调用了quitSafely方法。这个方法先判断是否能退出,然后再执行退出逻辑。如果mQuitting==true,那么这里会直接方法,我们会发现mQuitting这个变量只有在这里被执行了赋值,所以一旦looper退出,则无法再次运行了。之后执行不同的退出逻辑,我们分别看一下:
private void removeAllMessagesLocked() { Message p = mMessages; while (p != null) { Message n = p.next; p.recycleUnchecked(); p = n; } mMessages = null; }这个方法很简单,直接把当前所有的Message全部移除。再看一下另一个方法:
private void removeAllFutureMessagesLocked() { final long now = SystemClock.uptimeMillis(); Message p = mMessages; if (p != null) { // 如果都在等待,则全部移除,直接退出 if (p.when > now) { removeAllMessagesLocked(); } else { Message n; // 把需要等待的Message全部移除 for (;;) { n = p.next; if (n == null) { return; } if (n.when > now) { break; } p = n; } p.next = null; do { p = n; n = p.next; p.recycleUnchecked(); } while (n != null); } } }这个方法逻辑也不复杂,就是把需要等待的Message全部移除,当前需要执行的Message则保留。最终在MessageQueue的next方法中,会进行判断后返回null,表示退出,Looper收到这个返回值之后也跟着退出了。
Looper总结
Looper作为Handler消息机制的“动力引擎”,不断从MessageQueue中获取消息,然后交给Handler去处理。Looper的使用前需要先初始化当前线程的Looper对象,再调用loop方法来启动它。
同时Handler也是实现切换的核心,因为不同的Looper运行在不同的线程,他所调用的dispatchMessage方法则运行在不同的线程,所以Message的处理就被切换到Looper所在的线程了。当looper不再使用时,可调用不同的退出方法来退出他,注意Looper一旦退出,线程则会直接结束。
五、Handler
概述
我们整个消息机制称为Handler机制就可以知道Handler我们的使用频率之高,一般情况下我们的使用也是围绕着Handler来展开。Handler是作为整个消息机制的消息发起者与处理者,消息在不同的线程通过Handler发送到目标线程的MessageQueue中,然后目标线程的Looper再调用Handler的dispatchMessage方法来处理消息。
创建Handler
一般情况下我们使用Handler有两种方式: 继承Handler并重写handleMessage方法,直接创建Handler对象并传入callBack,这在前面使用Handler部分讲过就不再赘述。
需要注意的一点是:创建Handler必须显示指明Looper参数,而不能直接使用无参构造函数,如:
Handler handler = new Handler(); //1
Handler handler = new Handler(Looper.myLooper())//21是错的,2是对的。避免在Handler创建过程中Looper已经退出的情况。
发送消息
Handler发送消息有两种系列方法 : postxx 和 sendxx。如下:
public final boolean post(@NonNull Runnable r);
public final boolean postDelayed(@NonNull Runnable r, long delayMillis);
public final boolean postAtTime(@NonNull Runnable r, long uptimeMillis);
public final boolean postAtFrontOfQueue(@NonNull Runnable r);
public final boolean sendMessage(@NonNull Message msg);
public final boolean sendMessageDelayed(@NonNull Message msg, long delayMillis);
public boolean sendMessageAtTime(@NonNull Message msg, long uptimeMillis);
public final boolean sendMessageAtFrontOfQueue(@NonNull Message msg)这里我只列出了比较常用的两类方法。除了插在队列头的两个方法,其他方法最终都调用到了sendMessageAtTime。我们从post方法跟源码分析一下:
public final boolean post(@NonNull Runnable r) {
return sendMessageDelayed(getPostMessage(r), 0);
}post方法把runnable对象封装成一个Message,再调用sendMessageDelayed方法,我们看看他是如何封装的:
private static Message getPostMessage(Runnable r) {
Message m = Message.obtain();
m.callback = r;
return m;
}可以看到逻辑很简单,把runnable对象直接赋值给callBack属性。接下来回去继续看sendMessageDelayed:
public final boolean sendMessageDelayed(@NonNull Message msg, long delayMillis) {
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}
public boolean sendMessageAtTime(@NonNull Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}sendMessageDelayed把小于0的延迟时间改成0,然后调用sendMessageAtTime。这个方法主要是判断MessageQueue是否已经初始化了,然后再调用enqueueMessage方法进行入队操作:
private boolean enqueueMessage(@NonNull MessageQueue queue, @NonNull Message msg,
long uptimeMillis) {
// 这里把target设置成自己
msg.target = this;
msg.workSourceUid = ThreadLocalWorkSource.getUid();
// 异步handler设置标志位true,后面会讲到同步屏障
if (mAsynchronous) {
msg.setAsynchronous(true);
}
// 最后调用MessageQueue的方法入队
return queue.enqueueMessage(msg, uptimeMillis);
}可以看到Handler的入队操作也是很简单,把Message的target设置成本身,这样这个Message最后就是由自己来处理。最后调用MessageQueue的入队方法来入队,这在前面讲过就不再赘述。
其他的发送消息方法都是大同小异,读者感兴趣可以自己去跟踪一下源码。
处理消息
上面讲Looper处理消息的时候,最后就是调用handler的dispatchMessage方法来处理。我们来看一下这个方法:
public void dispatchMessage(@NonNull Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
handleMessage(msg);
}
}
private static void handleCallback(Message message) {
message.callback.run();
}他的逻辑也不复杂。首先判断Message是否有callBack,有的话就直接执行callBack的逻辑,这个callBack就是我们调用handler的post系列方法传进去的Runnable对象。否则判断Handler是否有callBack,有的话执行他的方法,如果返回true则结束,如果返回false则直接Handler本身的handleMessage方法。这个过程可以用下面的图表示一下:
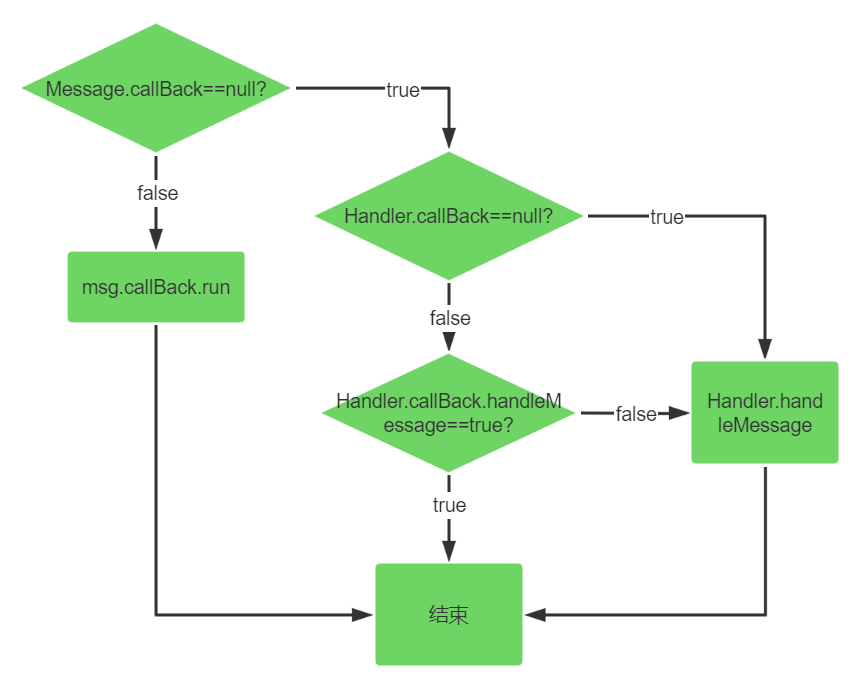
内存泄露问题
当我们使用继承Handler方法来使用Handler的时候,要注意使用静态内部类,而不要用非静态内部类。因为非静态内部类会持有外部类的引用,而从上面的分析我们知道Message在被入队之后他的target属性是指向了Handler,如果这个Message是一个延迟的消息,那么这一条引用链的对象就迟迟无法被释放,造成内存泄露。
一般这种泄露现象在于:我们在Activity中发送了一个延迟消息,然后退出了activity,但是由于无法释放,这样activity就无法被回收,造成内存泄露。
Handler总结
Handler作为消息的处理和发送者,是整个消息机制的起点和终点,也是我们接触最多的一个类,因为我们称此消息机制为Handler机制。Handler最重要的就是发送和处理消息,只要熟练掌握这两方面的内容就可以了。同时注意内存泄露问题,不要使用非静态内部类去继承Handler。
六、HandlerThread
概述
有时候我们需要开辟一个线程来执行一些耗时的任务。一般情况下可以通过新建一个Thread,然后再在他的run方法里初始化该线程的Looper,这样就可以用他的Looper来切线程处理消息了。如下(这里是kotlin代码,和java差不多相信可以看得懂的):
val thread = object : Thread(){
lateinit var mHandler: Handler
override fun run() {
super.run()
Looper.prepare()
mHandler = Handler(Looper.myLooper()!!)
Looper.loop()
}
}
thread.start()
thread.mHandler.sendMessage(Message.obtain())但是,运行一下,炸了:

Handler还未初始化。线程的启动需要一定的时间,就导致了这个问题,那简单,等待一下就可以了,上代码:
val thread = object : Thread(){
lateinit var mHandler: Handler
override fun run() {
super.run()
Looper.prepare()
mHandler = Handler(Looper.myLooper()!!)
Looper.loop()
}
}
thread.start()
Thread(){
Thread.sleep(10000)
thread.mHandler.sendMessage(Message.obtain())
}.start()执行一下,诶,没有报错了果然可以。但是!!! ,这样的代码显得特别的难堪和臃肿,还要再开启一个线程来延迟处理。那有没有更好的解决方案?有,HandlerThread。
HandlerThread本身是一个Thread,他继承自Thread,他的代码并不复杂,看一下(代码还是有点多,可以选择看或者不看,我下面会讲重点方法):
public class HandlerThread extends Thread {
// 依次是:线程优先级、线程id、线程looper、以及内部handler
int mPriority;
int mTid = -1;
Looper mLooper;
private @Nullable Handler mHandler;
// 两个构造器。name是线程名字,priority是线程优先级
public HandlerThread(String name) {
super(name);
mPriority = Process.THREAD_PRIORITY_DEFAULT;
}
public HandlerThread(String name, int priority) {
super(name);
mPriority = priority;
}
// 在Looper开始运行前的方法
protected void onLooperPrepared() {
}
// 初始化Looper
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
// 通知初始化完成
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}
// 获取当前线程的Looper
public Looper getLooper() {
if (!isAlive()) {
return null;
}
// 如果尚未初始化则会一直阻塞知道初始化完成
synchronized (this) {
while (isAlive() && mLooper == null) {
try {
// 利用Object对象的wait方法
wait();
} catch (InterruptedException e) {
}
}
}
return mLooper;
}
// 获取handler,该方法被标记为hide,用户无法获取
@NonNull
public Handler getThreadHandler() {
if (mHandler == null) {
mHandler = new Handler(getLooper());
}
return mHandler;
}
// 两种不同类型的退出,前面讲过不再赘述
public boolean quit() {
Looper looper = getLooper();
if (looper != null) {
looper.quit();
return true;
}
return false;
}
public boolean quitSafely() {
Looper looper = getLooper();
if (looper != null) {
looper.quitSafely();
return true;
}
return false;
}
// 获取线程id
public int getThreadId() {
return mTid;
}
}整个类的代码不是很多,重点在run()和getLooper()方法。首先看到getLooper方法:
public Looper getLooper() {
if (!isAlive()) {
return null;
}
// 如果尚未初始化则会一直阻塞知道初始化完成
synchronized (this) {
while (isAlive() && mLooper == null) {
try {
// 利用Object对象的wait方法
wait();
} catch (InterruptedException e) {
}
}
}
return mLooper;
}和我们前面自己写的不同,他有一个wait(),这个是Java中Object类提供的一个方法,类似于我们前面讲的MessageQueue阻塞。等到Looper初始化完成之后就会唤醒他,就可以顺利返回了,不会造成Looper尚未初始化完成的情况。然后再看到run方法:
// 初始化Looper
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
// 通知初始化完成
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}常规的Looper初始化,完成之后调用了notifyAll()方法进行唤醒,对应了上面的getLooper方法。
HandlerThread的使用
HandlerThread的使用范围很有限,开个子线程不断接受消息处理耗时任务。所以他的使用方法也是比较固定:
HandlerThread ht = new HandlerThread("handler");
Handler handler = new Hander(ht.getLooper());
handler.sendMessage(msg);获取到他的Looper,外部自定义Handler来使用即可。
七、总结
Handler,MessageQueue,Looper三者共同构成了android消息机制,各司其职。其中Handler主要负责发送和处理消息,MessageQueue主要负责消息的排序以及在没有需要处理的消息的时候阻塞代码,Looper负责从MessageQueue中取出消息给Handler处理,同时达到切换线程的目的。通过源码分析,希望读者可以对这些概念有更加清晰的认知。
工作流程
这一部分主要讲整体的流程,前面零零散散讲了各个组件的功能以及源码,现在就统一来讲一下他们的整体流程。先看图:
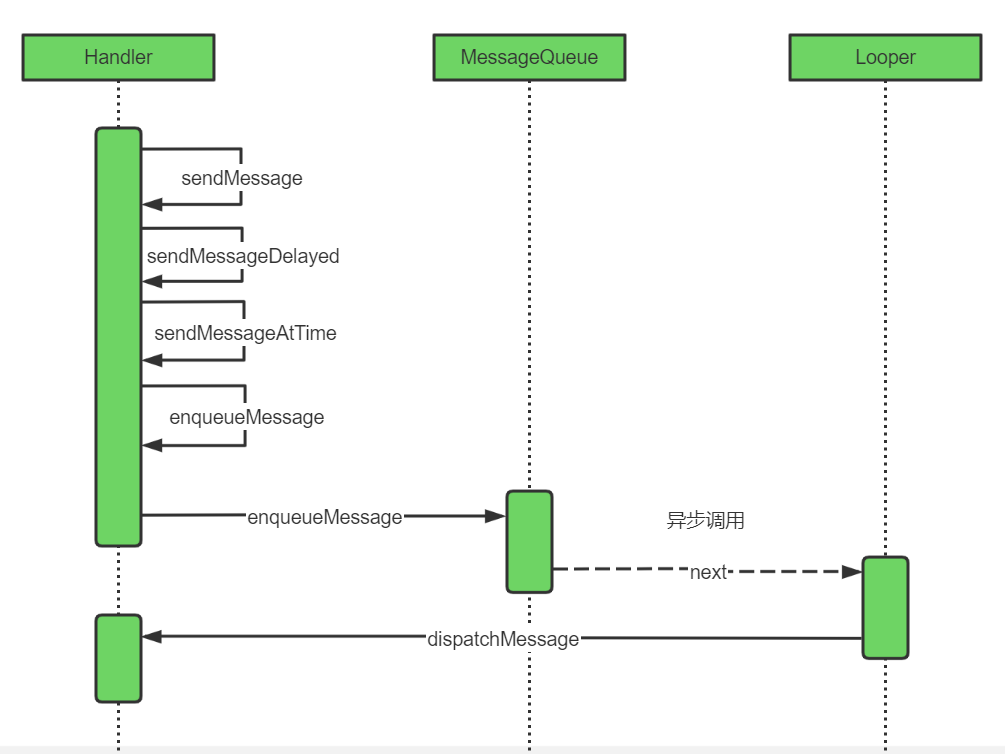
- Handler设置一系列的api供给开发者可以使用Handler发送各种类型的信息,最终都调用到了enqueueMessage方法来入队
- 调用MessageQueue的enqueueMessage方法把消息插入到MessageQueue的链表中,等待被Looper获取处理
- Looper获取到Message之后,调用Message对应的Handler处理Message
这样整理的流程就清晰了,细节的源码分析我就不再赘述了,如果有读者哪个部分不够清晰,可以回到上面对应部分再看一遍。
相关问题
主线程为什么不用初始化Looper?
答:因为应用在启动的过程中就已经初始化主线程Looper了。
每个java应用程序都是有一个main方法入口,Android是基于Java的程序也不例外。Android程序的入口在ActivityThread的main方法中:
public static void main(String[] args) {
...
// 初始化主线程Looper
Looper.prepareMainLooper();
...
// 新建一个ActivityThread对象
ActivityThread thread = new ActivityThread();
thread.attach(false, startSeq);
// 获取ActivityThread的Handler,也是他的内部类H
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
...
Looper.loop();
// 如果loop方法结束则抛出异常,程序结束
throw new RuntimeException("Main thread loop unexpectedly exited");
}main方法中先初始化主线程Looper,新建ActivityThread对象,然后再启动Looper,这样主线程的Looper在程序启动的时候就跑起来了。我们不需要再去初始化主线程Looper。
为什么主线程的Looper是一个死循环,但是却不会ANR?
答: 因为当Looper处理完所有消息的时候会进入阻塞状态,当有新的Message进来的时候会打破阻塞继续执行。
这其实没理解好ANR这个概念。ANR,全名Application Not Responding。当我发送一个绘制UI 的消息到主线程Handler之后,经过一定的时间没有被执行,则抛出ANR异常。Looper的死循环,是循环执行各种事务,包括UI绘制事务。Looper死循环说明线程没有死亡,如果Looper停止循环,线程则结束退出了。Looper的死循环本身就是保证UI绘制任务可以被执行的原因之一。同时UI绘制任务有同步屏障,可以更加快速地保证绘制更快执行。同步屏障下面会讲。
Handler如何保证MessageQueue并发访问安全?
答:循环加锁,配合阻塞唤醒机制。
我们可以发现MessageQueue其实是“生产者-消费者”模型,Handler不断地放入消息,Looper不断地取出,这就涉及到死锁问题。如果Looper拿到锁,但是队列中没有消息,就会一直等待,而Handler需要把消息放进去,锁却被Looper拿着无法入队,这就造成了死锁。Handler机制的解决方法是循环加锁。在MessageQueue的next方法中:
Message next() {
...
for (;;) {
...
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this) {
...
}
}
}我们可以看到他的等待是在锁外的,当队列中没有消息的时候,他会先释放锁,再进行等待,直到被唤醒。这样就不会造成死锁问题了。
那在入队的时候会不会因为队列已经满了然后一边在等待消息处理一边拿着锁呢?这一点不同的是MessageQueue的消息没有上限,或者说他的上限就是JVM给程序分配的内存,如果超出内存会抛出异常,但一般情况下是不会的。
Looper退出后是否可以重新运行?
答: 不可以。
线程的存活是靠Looper调用的next方法进行阻塞实现的。如果Looper退出后,那么线程会马上结束,也不会再有第二次运行的机会了。即使线程还没结束再一次调用loop(),Looper内部有一个mQuitting变量,当他被赋值为false之后就无法再被赋值为true。所以就无法再重新运行了。
Handler是如何切换线程的?
答: 使用不同线程的Looper处理消息。
前面我们聊到,代码的执行线程,并不是代码本身决定,而是执行这段代码的逻辑是在哪个线程,或者说是哪个线程的逻辑调用的。每个Looper都运行在对应的线程,所以不同的Looper调用的dispatchMessage方法就运行在其所在的线程了。
Handler的阻塞唤醒机制是怎么回事?
答: Handler的阻塞唤醒机制是基于Linux的阻塞唤醒机制。
这个机制也是类似于handler机制的模式。在本地创建一个文件描述符,然后需要等待的一方则监听这个文件描述符,唤醒的一方只需要修改这个文件,那么等待的一方就会收到文件从而打破唤醒。和Looper监听MessageQueue,Handler添加message是比较类似的。具体的Linux层知识读者可通过这篇文章详细了解(传送门)
能不能让一个Message加急被处理?/ 什么是Handler同步屏障?
答:可以 / 一种使得异步消息可以被更快处理的机制
如果向主线程发送了一个UI更新的操作Message,而此时消息队列中的消息非常多,那么这个Message的处理就会变得缓慢,造成界面卡顿。所以通过同步屏障,可以使得UI绘制的Message更快被执行。
什么是同步屏障?这个“屏障”其实是一个Message,插入在MessageQueue的链表头,且其target==null。Message入队的时候不是判断了target不能为null吗?不不不,添加同步屏障是另一个方法:
public int postSyncBarrier() {
return postSyncBarrier(SystemClock.uptimeMillis());
}
private int postSyncBarrier(long when) {
synchronized (this) {
final int token = mNextBarrierToken++;
final Message msg = Message.obtain();
msg.markInUse();
msg.when = when;
msg.arg1 = token;
Message prev = null;
Message p = mMessages;
// 把当前需要执行的Message全部执行
if (when != 0) {
while (p != null && p.when <= when) {
prev = p;
p = p.next;
}
}
// 插入同步屏障
if (prev != null) { // invariant: p == prev.next
msg.next = p;
prev.next = msg;
} else {
msg.next = p;
mMessages = msg;
}
return token;
}
}可以看到同步屏障就是一个特殊的target,哪里特殊呢?target==null,我们可以看到他并没有给target属性赋值。那这个target有什么用呢?看next方法:
Message next() {
...
// 阻塞时间
int nextPollTimeoutMillis = 0;
for (;;) {
...
// 阻塞对应时间
nativePollOnce(ptr, nextPollTimeoutMillis);
// 对MessageQueue进行加锁,保证线程安全
synchronized (this) {
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
/**
* 1
*/
if (msg != null && msg.target == null) {
// 同步屏障,找到下一个异步消息
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
// 下一个消息还没开始,等待两者的时间差
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// 获得消息且现在要执行,标记MessageQueue为非阻塞
mBlocked = false;
/**
* 2
*/
// 一般只有异步消息才会从中间拿走消息,同步消息都是从链表头获取
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
msg.markInUse();
return msg;
}
} else {
// 没有消息,进入阻塞状态
nextPollTimeoutMillis = -1;
}
// 当调用Looper.quitSafely()时候执行完所有的消息后就会退出
if (mQuitting) {
dispose();
return null;
}
...
}
...
}
}这个方法我在前面讲过,我们重点看一下关于同步屏障的部分,看注释1的地方的代码:
if (msg != null && msg.target == null) {
// 同步屏障,找到下一个异步消息
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}如果遇到同步屏障,那么会循环遍历整个链表找到标记为异步消息的Message,即isAsynchronous返回true,其他的消息会直接忽视,那么这样异步消息,就会提前被执行了。注释2的代码注意一下就可以了。
注意,同步屏障不会自动移除,使用完成之后需要手动进行移除,不然会造成同步消息无法被处理。从源码中可以看到如果不移除同步屏障,那么他会一直在那里,这样同步消息就永远无法被执行了。
有了同步屏障,那么唤醒的判断条件就必须再加一个:MessageQueue中有同步屏障且处于阻塞中,此时插入在所有异步消息前插入新的异步消息。这个也很好理解,跟同步消息是一样的。如果把所有的同步消息先忽视,就是插入新的链表头且队列处于阻塞状态,这个时候就需要被唤醒了。看一下源码:
boolean enqueueMessage(Message msg, long when) {
...
// 对MessageQueue进行加锁
synchronized (this) {
...
if (p == null || when == 0 || when < p.when) {
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
/**
* 1
*/
// 当线程被阻塞,且目前有同步屏障,且入队的消息是异步消息
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
/**
* 2
*/
// 如果找到一个异步消息,说明前面有延迟的异步消息需要被处理,不需要被唤醒
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p;
prev.next = msg;
}
// 如果需要则唤醒队列
if (needWake) {
nativeWake(mPtr);
}
}
return true;
}同样,这个方法我之前讲过,把无关同步屏障的代码忽视,看到注释1处的代码。如果插入的消息是异步消息,且有同步屏障,同时MessageQueue正处于阻塞状态,那么就需要唤醒。而如果这个异步消息的插入位置不是所有异步消息之前,那么不需要唤醒,如注释2。
那我们如何发送一个异步类型的消息呢?有两种办法:
- 使用异步类型的Handler发送的全部Message都是异步的
- 给Message标志异步
Handler有一系列带Boolean类型的参数的构造器,这个参数就是决定是否是异步Handler:
public Handler(@NonNull Looper looper, @Nullable Callback callback, boolean async) {
mLooper = looper;
mQueue = looper.mQueue;
mCallback = callback;
// 这里赋值
mAsynchronous = async;
}在发送消息的时候就会给Message赋值:
private boolean enqueueMessage(@NonNull MessageQueue queue, @NonNull Message msg,
long uptimeMillis) {
msg.target = this;
msg.workSourceUid = ThreadLocalWorkSource.getUid();
// 赋值
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}但是异步类型的Handler构造器是标记为hide,我们无法使用,所以我们使用异步消息只有通过给Message设置异步标志:
public void setAsynchronous(boolean async) {
if (async) {
flags |= FLAG_ASYNCHRONOUS;
} else {
flags &= ~FLAG_ASYNCHRONOUS;
}
}但是!!!!,其实同步屏障对于我们的日常使用的话其实是没有多大用处。因为设置同步屏障和创建异步Handler的方法都是标志为hide,说明谷歌不想要我们去使用他。所以这里同步屏障也作为一个了解,可以更加全面地理解源码中的内容。
什么是IdleHandler?
答: 当MessageQueue为空或者目前没有需要执行的Message时会回调的接口对象。
IdleHandler看起来好像是个Handler,但他其实只是一个有单方法的接口,也称为函数型接口:
public static interface IdleHandler {
boolean queueIdle();
}在MessageQueue中有一个List存储了IdleHandler对象,当MessageQueue没有需要被执行的MessageQueue时就会遍历回调所有的IdleHandler。所以IdleHandler主要用于在消息队列空闲的时候处理一些轻量级的工作。
IdleHandler的调用是在next方法中:
Message next() {
// 如果looper已经退出了,这里就返回null
final long ptr = mPtr;
if (ptr == 0) {
return null;
}
// IdleHandler的数量
int pendingIdleHandlerCount = -1;
// 阻塞时间
int nextPollTimeoutMillis = 0;
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
// 阻塞对应时间
nativePollOnce(ptr, nextPollTimeoutMillis);
// 对MessageQueue进行加锁,保证线程安全
synchronized (this) {
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null) {
// 同步屏障,找到下一个异步消息
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
// 下一个消息还没开始,等待两者的时间差
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// 获得消息且现在要执行,标记MessageQueue为非阻塞
mBlocked = false;
// 一般只有异步消息才会从中间拿走消息,同步消息都是从链表头获取
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
msg.markInUse();
return msg;
}
} else {
// 没有消息,进入阻塞状态
nextPollTimeoutMillis = -1;
}
// 当调用Looper.quitSafely()时候执行完所有的消息后就会退出
if (mQuitting) {
dispose();
return null;
}
// 当队列中的消息用完了或者都在等待时间延迟执行同时给pendingIdleHandlerCount<0
// 给pendingIdleHandlerCount赋值MessageQueue中IdleHandler的数量
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
// 没有需要执行的IdleHanlder直接continue
if (pendingIdleHandlerCount <= 0) {
// 执行IdleHandler,标记MessageQueue进入阻塞状态
mBlocked = true;
continue;
}
// 把List转化成数组类型
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
// 执行IdleHandler
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // 释放IdleHandler的引用
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
// 如果返回false,则把IdleHanlder移除
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
// 最后设置pendingIdleHandlerCount为0,防止再执行一次
pendingIdleHandlerCount = 0;
// 当在执行IdleHandler的时候,可能有新的消息已经进来了
// 所以这个时候不能阻塞,要回去循环一次看一下
nextPollTimeoutMillis = 0;
}
}
代码很多,可能看着有点乱,我梳理一下逻辑,然后再回去看源码就会很清晰了:
- 当调用next方法的时候,会给
pendingIdleHandlerCount赋值为-1 - 如果队列中没有需要处理的消息的时候,就会判断
pendingIdleHandlerCount是否为<0,如果是则把存储IdleHandler的list的长度赋值给pendingIdleHandlerCount - 把list中的所有IdleHandler放到数组中。这一步是为了不让在执行IdleHandler的时候List被插入新的IdleHandler,造成逻辑混乱
- 然后遍历整个数组执行所有的IdleHandler
- 最后给
pendingIdleHandlerCount赋值为0。然后再回去看一下这个期间有没有新的消息插入。因为pendingIdleHandlerCount的值为0不是-1,所以IdleHandler只会在空闲的时候执行一次 - 同时注意,如果IdleHandler返回了false,那么执行一次之后就被丢弃了。
建议读者再回去把源码看一遍,这样逻辑会清晰很多。
Handler消息机制的再认识
到这里关于Handler机制该讲的已经讲得差不多了。但不知读者和我一样是否有同样的疑惑:
Handler机制为什么叫做Android中的消息机制?Handler真的就只是用来切换线程更新UI 的吗?怎么样从源码设计的角度来更好地理解Handler消息机制?
每次学习关于Android中的机制问题时,我都喜欢从研究他在android源码设计中体现的作用,或者说思想。这有助于让我的理解提高一个层次。这里就简单谈谈我对Handler机制的理解。
Handler机制,之所以叫handler,我觉得只是因为我们接触的都是Handler,所以叫做Handler机制,如果我们接触Looper比较多可能他的名字就是Looper机制了。更准确来说,他应该是Android消息机制。
我们知道,每个java程序都有一个入口:main方法,然后我们从这里开始进入我们的应用程序。相信每个读者都有使用c语言写学生管理系统的经历,我们是如何让程序暂停下来不要直接结束的?通过循环+输入等待。我们会在最外层写一个死循环,然后不断地监听输入,再根据输入执行命令。当用户无输入的时候,就会一直等待。这其实和Handler机制是类似的。Handler机制使用的是多线程的思路,主线程不断等待消息,然后从别的线程发送消息让主线程执行逻辑,这也称为事务驱动型设计,主线程的逻辑都是通过message来驱动的。
我们直接来看一下Android应用程序的main方法:
public static void main(String[] args) {
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "ActivityThreadMain");
AndroidOs.install();
CloseGuard.setEnabled(false);
Environment.initForCurrentUser();
final File configDir = Environment.getUserConfigDirectory(UserHandle.myUserId());
TrustedCertificateStore.setDefaultUserDirectory(configDir);
Process.setArgV0("<pre-initialized>");
// 初始化Looper
Looper.prepareMainLooper();
long startSeq = 0;
if (args != null) {
for (int i = args.length - 1; i >= 0; --i) {
if (args[i] != null && args[i].startsWith(PROC_START_SEQ_IDENT)) {
startSeq = Long.parseLong(
args[i].substring(PROC_START_SEQ_IDENT.length()));
}
}
}
// 创建ActivityThread
ActivityThread thread = new ActivityThread();
thread.attach(false, startSeq);
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
if (false) {
Looper.myLooper().setMessageLogging(new
LogPrinter(Log.DEBUG, "ActivityThread"));
}
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
// 启动Looper
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}但是我们可以看到他的代码其实并不多,启动了ActivityThread和Looper之后就没有再执行其他逻辑了,那我们的Activity是如何被调用并执行逻辑的?通过Handler。Android是事务驱动型的设计,通过不断地分发事务来让整个程序运行起来。熟悉Activity启动流程的读者应该可以联想到,AMS通过binder机制和程序联系,然后binder线程再发送一个消息给到主线程,主线程再执行相对应的逻辑。他们的关系可以用下面的图来表示:
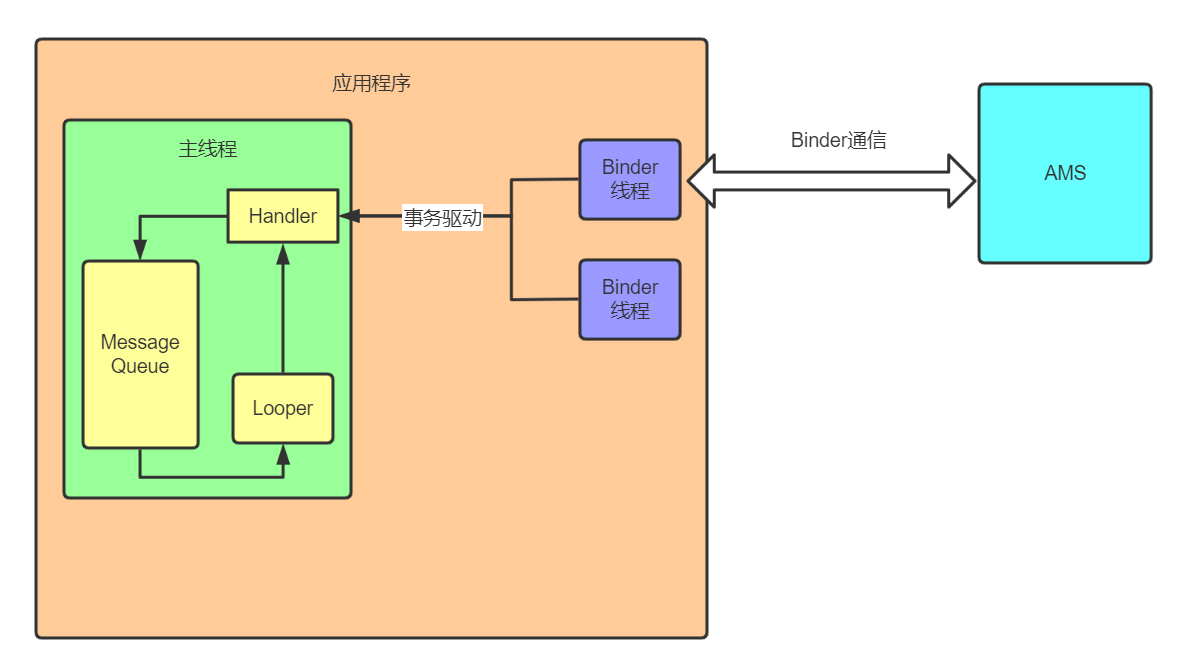
当应用进程被创建的时候,只是创建了主线程的Looper和handler,以及其他的binder线程等。之后AMS通过Binder与应用程序通信,给主线程发送message,让程序执行创建Activity等的操作。这样的设计我们不用去写死循环和等待用户输入等逻辑,应用程序就能跑起来且不会结束。关于Activity的启动相关我这里就不展开讲了,读者可以去看笔者的另一篇文章(Activity启动流程详解)。之后程序会开启其他的线程来接收用户的触摸输入等,然后把这些包装成一个message发送到主线程去更新UI。
可以说,“无消息,无安卓”,整个安卓的程序运行都是基于这套消息机制来跑的。他不仅仅只是切换线程这么简单,他涉及到整个android程序的根基。
总结
这篇文章从一开始的入门讲解,到深入讲解各个类的源码和作用,最后再升华一下整个消息机制的设计思想。相信读者关于Handler消息机制的认识已经非常深刻了。
消息机制我们日常使用得并不多,虽然他非常重要,但我们的使用也是主要用户切换线程更新UI这一块。而我们有很多成熟且非常方便的框架可以使用:RxJava、kotlin协程等等。但由于Handler机制对于android程序实在是非常重要,对于深入学习android还是非常有必要去学习、去理解。
希望文章对你有帮助。
全文到此,原创不易,觉得有帮助可以点赞收藏评论转发。
笔者才疏学浅,有任何想法欢迎评论区交流指正。
如需转载请私信交流。另外欢迎光临笔者的个人博客:传送门







